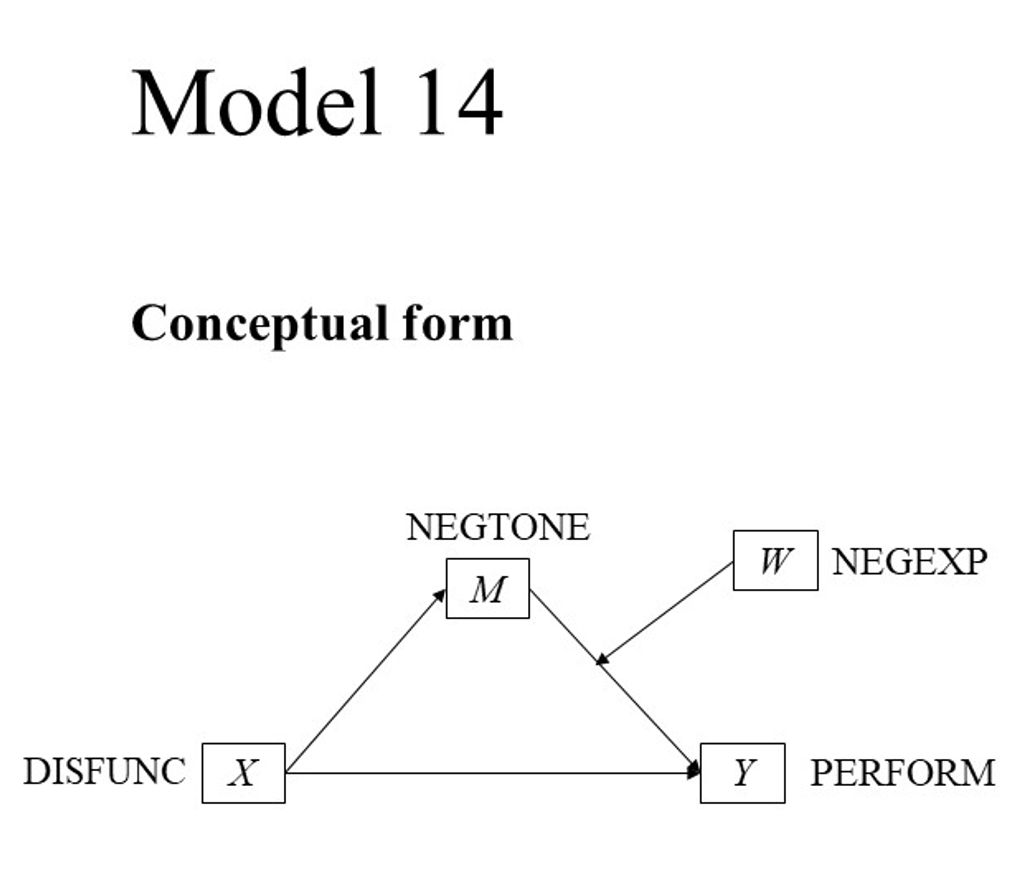
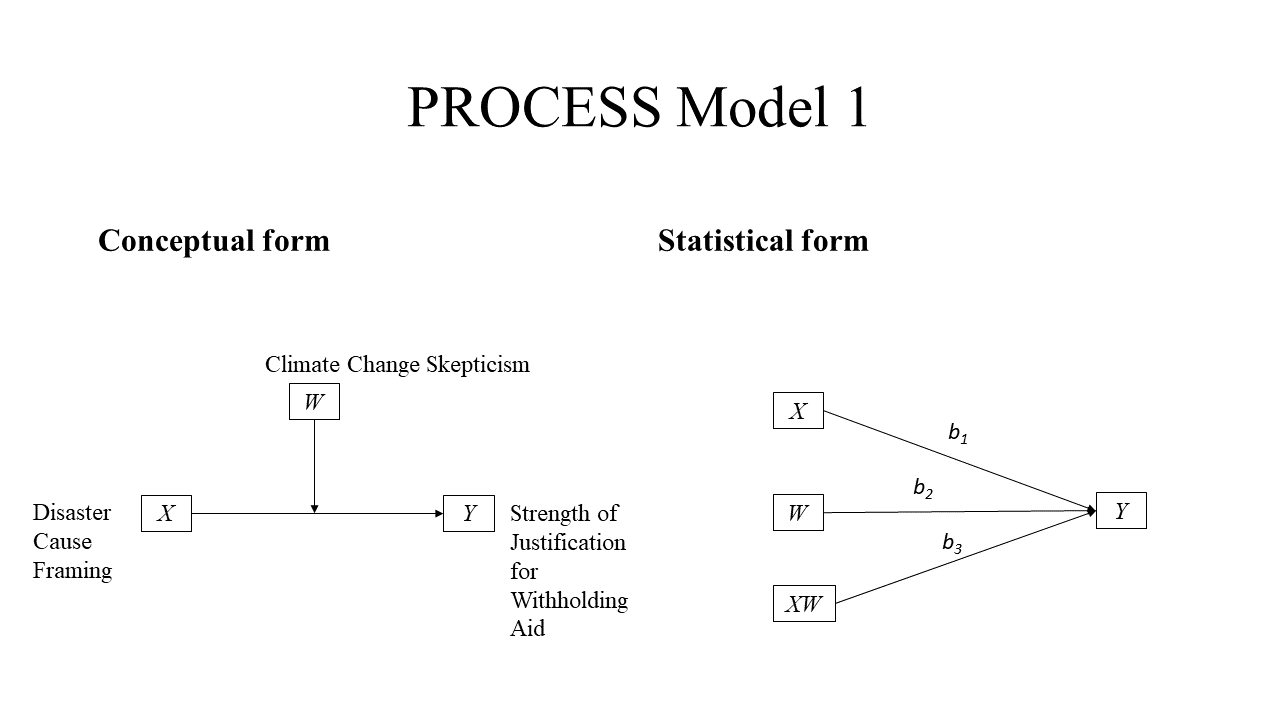
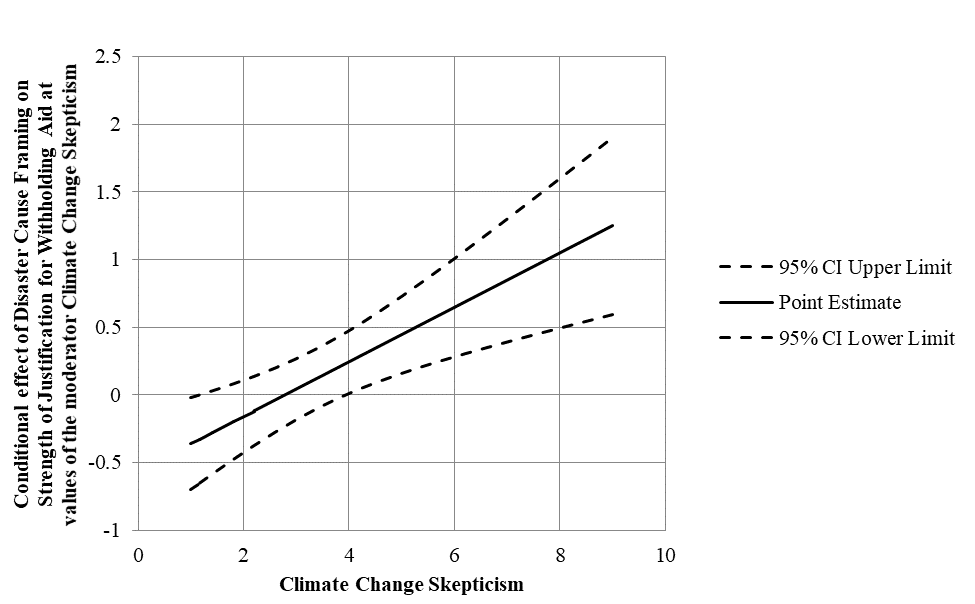
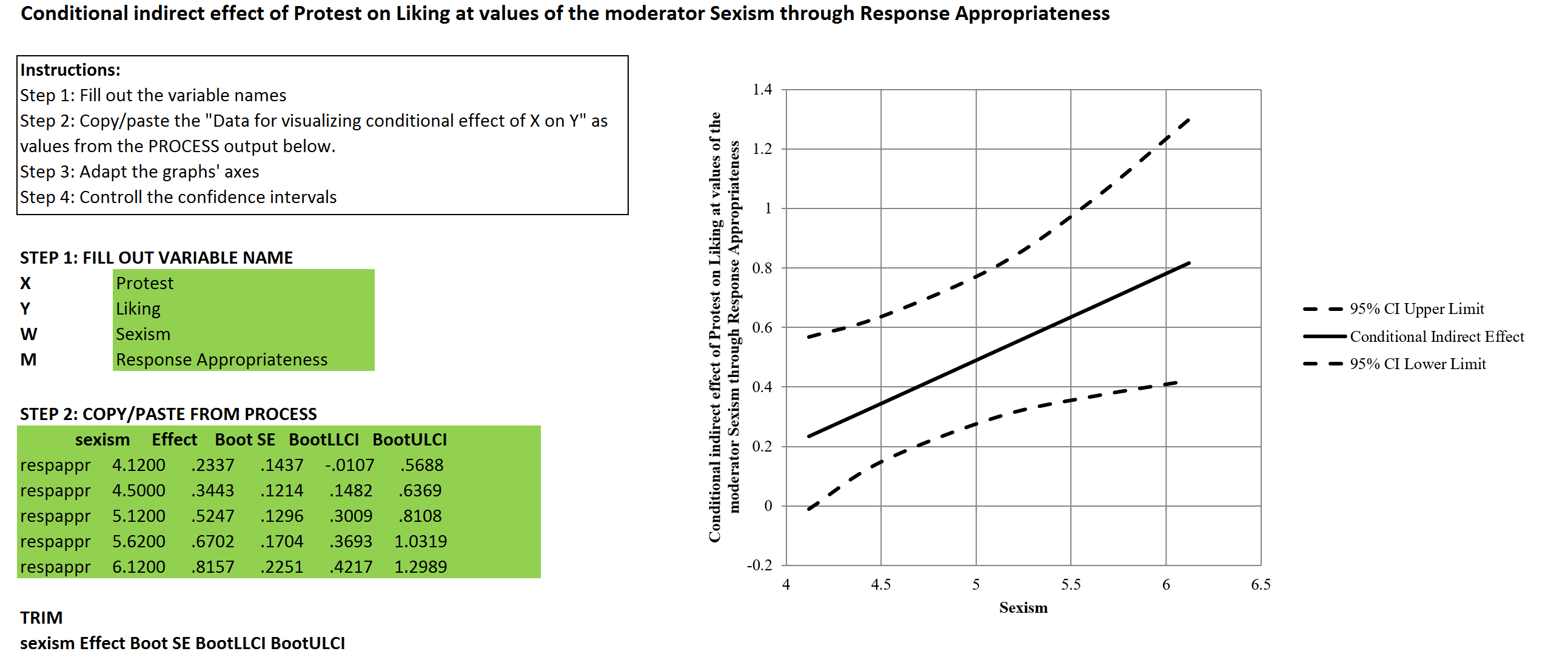
Imagine you are an HR-Manager, and you would like to know which employees are likely to stay, and which might leave your company. Besides you would like to understand which factors contribute to leaving your company. You have gathered data in the past (well, in this case Kaggle simulated a dataset for you, but just imagine), and now you can start with this Hands On Lab – Predict Employee Leave to build your prediction model to see if that can help you.
In this lab, you will learn how to create a machine learning module that predicts whether an employee will stay or leave your company. We are aware of the limitations of the dataset but the objective of this hands on lab is to inspire you to explore the possibilities of using machine learning for your own research, and not to build the next HR-solution.
We created a starting experiment for you on the Azure AI Gallery to give you a smooth start. Continue reading “Human Resources Analytics – Predict Employee Leave”