

This is a simple example about optimizing prediction models on Azure. In this case we will use a Boosted Decision Tree model. We will show you how you can use the Permutation Feature Performance module to prune your trees.
We start with the Student Performance Classifier from a previous blog. We already found out that the Boosted Decision Tree algorithm gave the best results, so we will start with that one to train our model with.
The corresponding experiment can be downloaded from the Cortana Intelligence Gallery.
Let’s start with the original model. We used the data from a math class to predict the result of a student for that particular subject. We start with all the data (details can be found in the blog), not knowing which of the 31 variables (we excluded G3 as we converted that value to the result) could be important.
Reproducibility: set the seeds
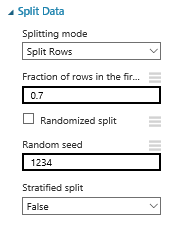
To make this sample reproducible, we set a seed when splitting the data:
Training the first model: get the best hyperparameter settings
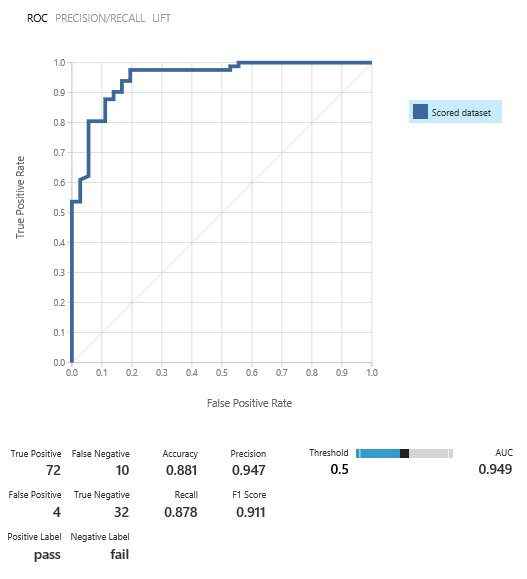
Now we are ready to train the model. As we don’t know what settings to use, we select the Tune Model Hyperparameters module to get the optimum setting. In this case we are training for Accuracy and we allow 30 rounds to train the model. This can be time-consuming but you have to do this only once.

And with these setting, we are doing pretty ok:
Training the second model: use the best hyperparameter settings
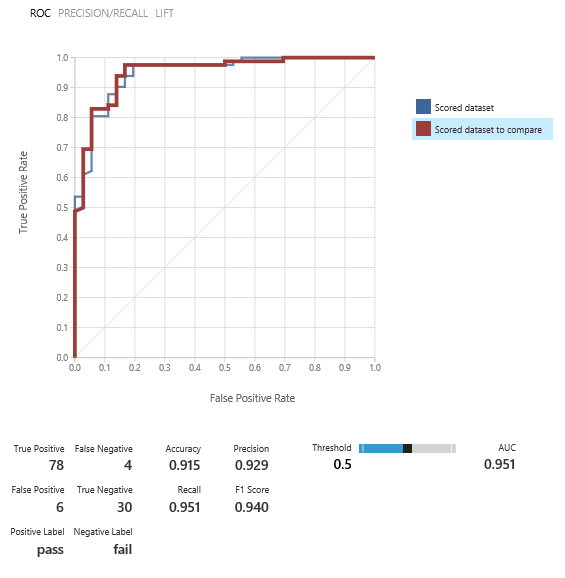
We are ready to train a second model, using the hyperparameter settings from the prior step, which will save us training time, and the results are very close:
How to find out the importance of the variables: use the Permutation Feature Importance module
Now we add the Permutation Feature Importance module to check the importance of the various variables. We strive for good accuracy, so we chose that metric to focus on. It’s important to set the seed as well, to make it repeatable.
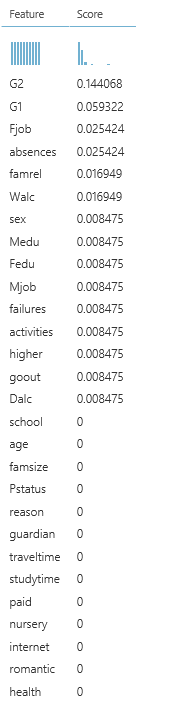
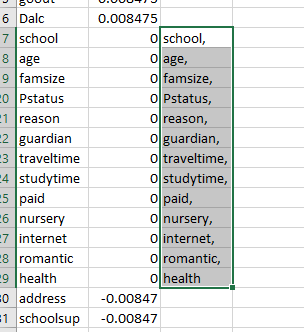
We see that the last grades (G2 and G1) are important, followed by a father’s job, absences etc. But we also see that variables as school, age and family size, etc. have zero importance.
Prune the trees step 1: eliminate the variables with zero importance
There is a little trick to make this easy: if you connect a Convert to csv module to the Permutation Feature Importance module, you can download this csv to Excel. Then you can concatenate the variable name and a comma, and paste it to a Select column module.
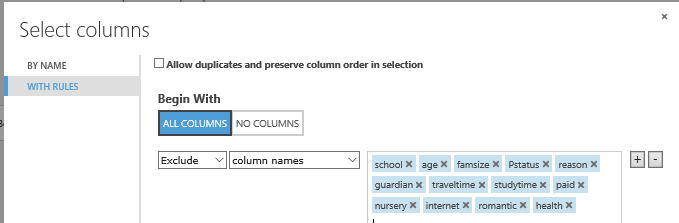
Prune the trees step 2: training the third model using the reduced amount of variables
Now we are going to train a third model, using the same hyperparameter settings as before.
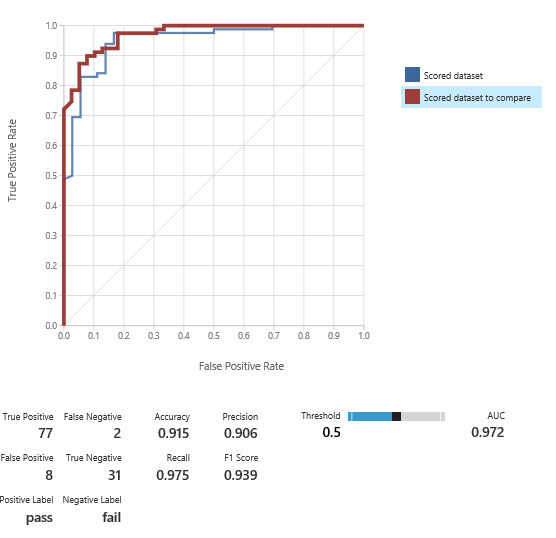
And we are doing very well, with a reduced amount of predictors.
Prune the trees step 3: repeat!
We repeated step 1 and 2 and trained a fourth model. The results look very well, and remember, we are using a limited set of predictors:
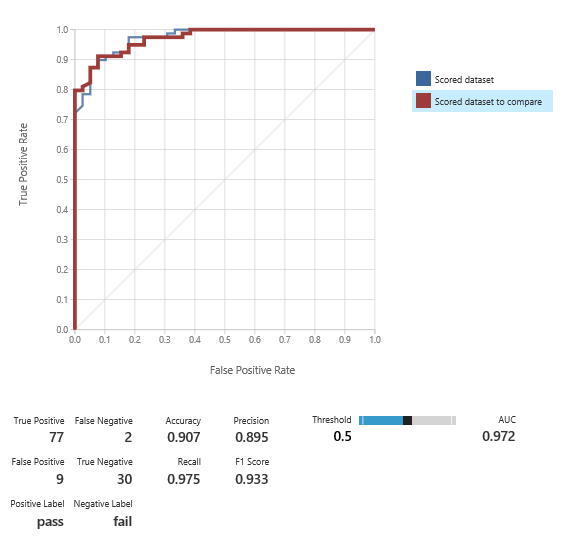
However, we still find variables with zero importance:
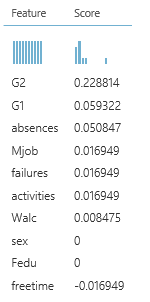
So we’ll repeat step 1 and 2 another time and train model five:
And although the results are very good, we still have variables with zero importance:

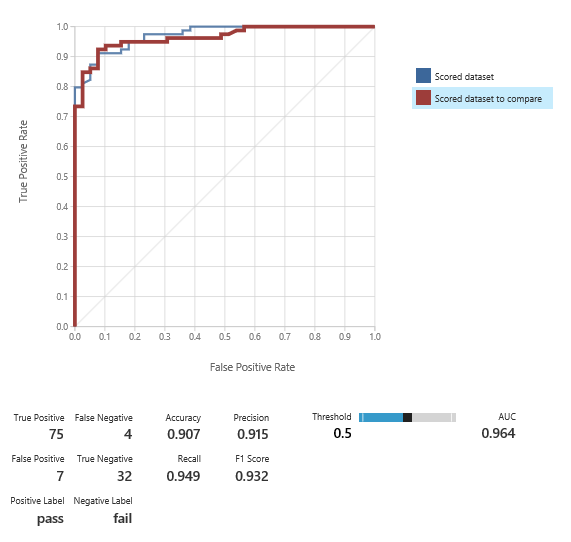
So we train model six:
And the results are still good.
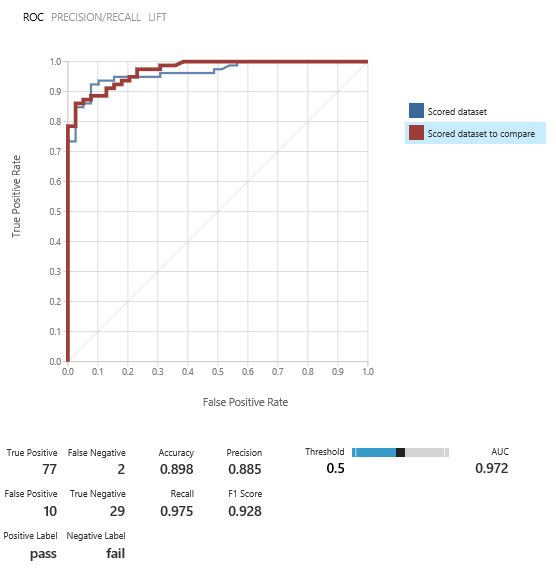
Prune the threes step 4: enough is enough
Now we have trained enough models and all our variables have an importance other than zero:
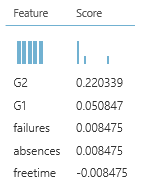
So from the 31 possible predictors, we actually can make a nice model, just using 5 of them. Off course, when it’s easy to obtain data, you don’t have to prune that much, but sometimes it’s hard to get data, and by pruning, you can obtain good results with less predictors.