This tutorial is about graphing a simple moderation model with PROCESS for R, developed by Andrew Hayes, and my MD2C graphing template. There is a Github Repository for it as well, containing the R code.
Frequently Asked Questions about how to use the PROCESS templates
This FAQ PROCESS overview can hopefully help you to use my templates to graph conditional effects. They are made for the PROCESS macro from Andrew Hayes to calculate conditional effects within SPSS.
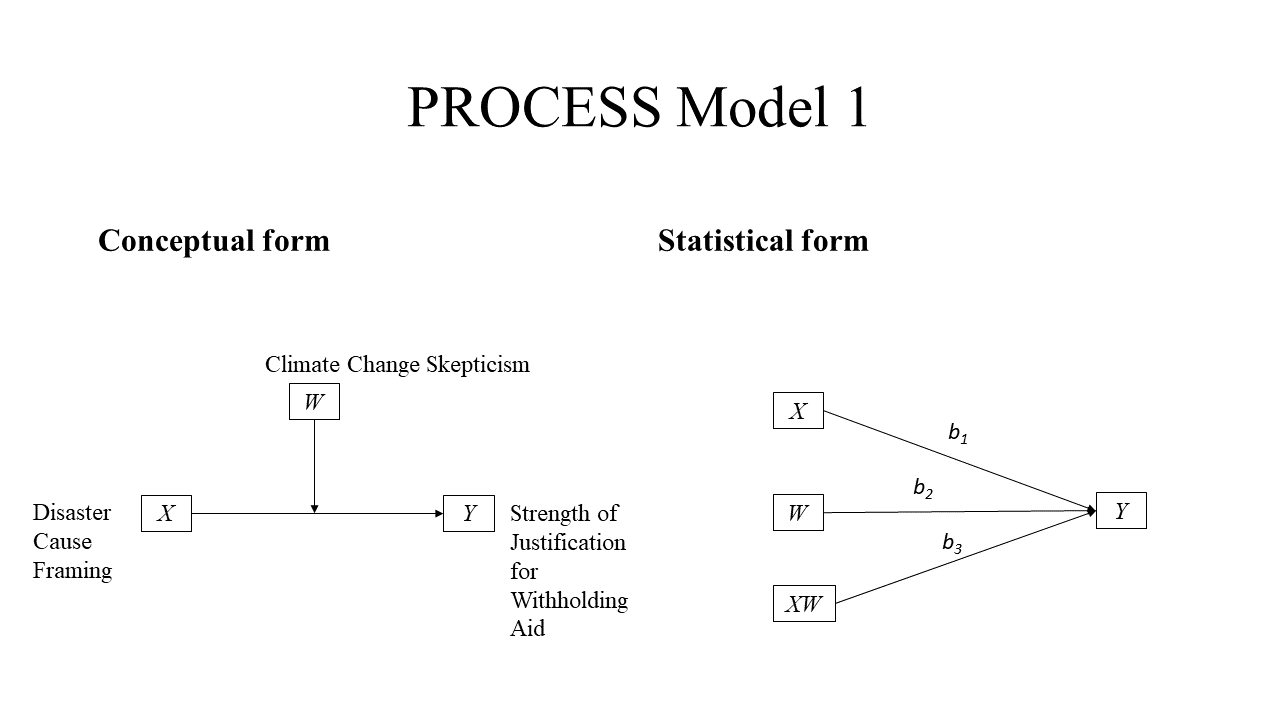
Graphing moderation (PROCESS v3.0) – Model 1 (continuous IV) (Windows version), with a continous independent variable (X), a continuous dependent variable (Y), and a continuous moderator (W). As some of you requested, the IV is on the x-axis, and the moderator in the legend. Click here for the Mac version.
Graphing moderated moderation (PROCESS v3.0) – Model 3 (Windows version), with a continuous independent variable (X) Negative Emotions, a continuous dependent variable (Y) Support for Government Action, a categorical moderator (W) Sex, and a continuous moderator (Z) Age. Click here for the Mac version.
Graphing moderated mediation (PROCESS v2.16) – Model 8 (Windows version), with a dichotomous independent variable (X), and a continuous moderator (W), mediator (M) and dependent variable (Y). As this is based on an earlier version of PROCESS, we are discontinuing the development of this template and recommend you to use V3.
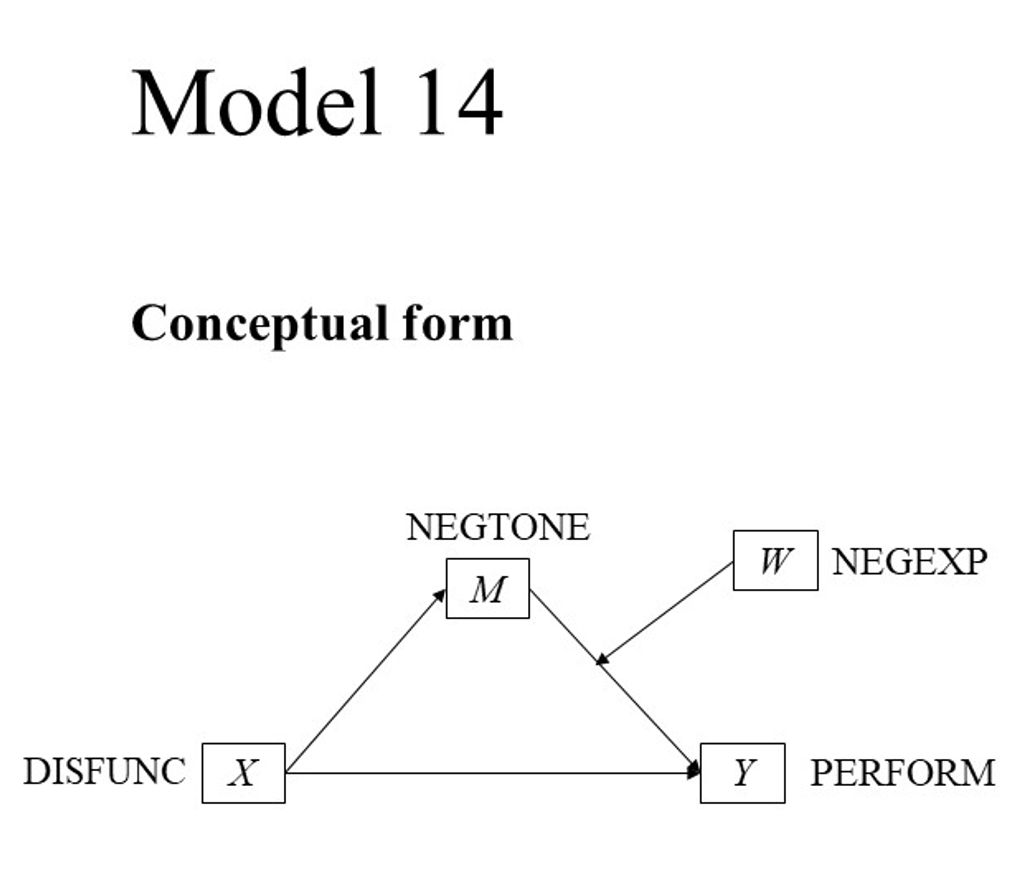
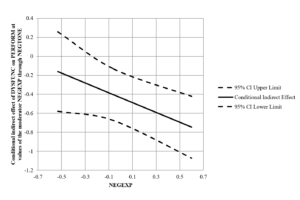
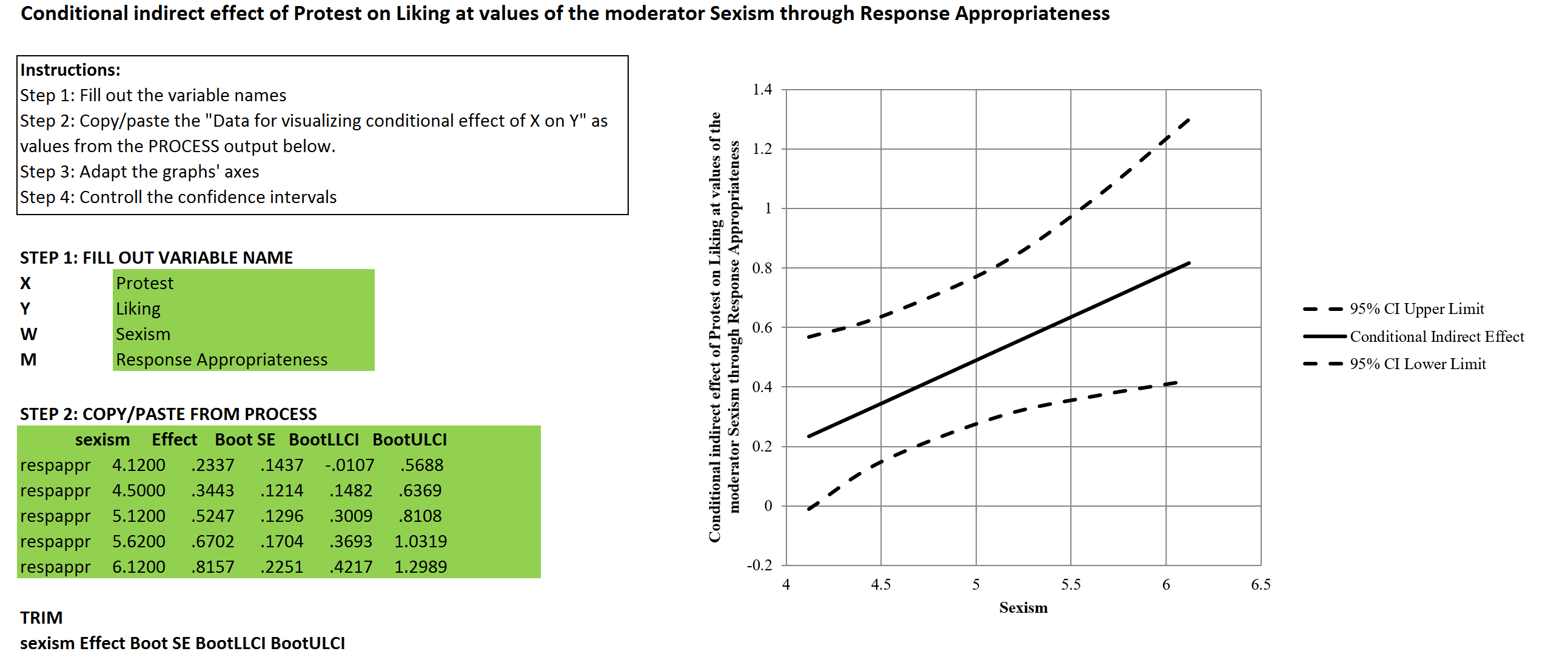
Graphing moderated mediation (PROCESS v3.0) – Model 14 (Windows version), with a continuous independent variable (X) Dysfunctional Behavior, a continuous dependent variable (Y) Work Performance, a continuous mediator (M) Negative Affective Tone, and a continuous moderator (W) Nonverbal Negative Expressivity. Click here for the Mac version.
I am very thankful for all the great feedback and questions we are receiving from fellow-researchers, and I hope that you will continue doing this.
With this list of Frequently Asked Question, I am trying to cover most of the questions, but please don’t hesitate to reach out to me!
FAQ PROCESS Questions & Answers
FAQ PROCESSQuestion: I can’t see any graph, what goes wrong?
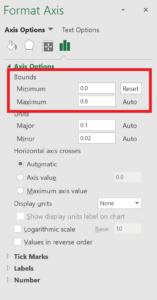
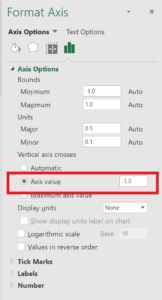
Answer: Please check first if you have “.” or “,” as a decimal separator. The templates require a “.” as decimal separator. A quick solution could be the usage of “find-and-replace” in Excel, where you replace the “,” for the “.” for the input rows. Secondly, please check the axis of the graph: sometimes you have to reset them by right-clicking on the required axis, select “Format Axis”, and reset the Minimum and/or Maximum Bounds values.
FAQ PROCESSQuestion: The axis are crossing the middle of the graphs (mostly at value 0), what can I do?
Answer: you can right-click on the required axis, select “Format Axis”, and set the value at which the axis crosses
FAQ PROCESS Question: There isn’t a template for my model, can you make one?
Answer: if you could contact us, and provide us the data (we won’t use it other than just for inspection and possible creation of the template), we can let you know if that is possible or not.
FAQ PROCESSQuestion: I haven’t received the download link, what can I do?
Answer: it could take some business days to process the paypal transfer, but sometimes, the email is in your spambox of emails are blocked. In any case: please feel free to reach out to me and I will make sure you will get your template. You can reach me by sending an email to info [at] md2c [dot] nl
FAQ PROCESSQuestion: I can’t download the template, what can I do?
Answer: please check your browser. The download works best with Mozilla or Edge, and does not work correctly with Chrome currently. In any case: please feel free to reach out to me and I will make sure you will get your template. You can reach me by sending an email to info [at] md2c [dot] nl
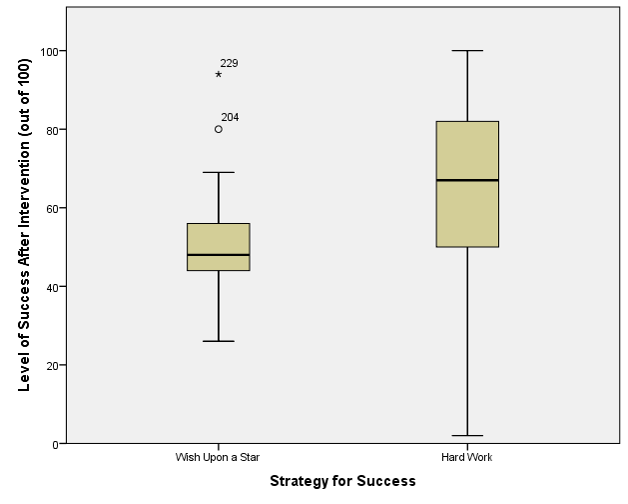
Imagine you are an HR-Manager, and you would like to know which employees are likely to stay, and which might leave your company. Besides you would like to understand which factors contribute to leaving your company. You have gathered data in the past (well, in this case Kaggle simulated a dataset for you, but just imagine), and now you can start with this Hands On Lab – Predict Employee Leave to build your prediction model to see if that can help you.
In this lab, you will learn how to create a machine learning module that predicts whether an employee will stay or leave your company. We are aware of the limitations of the dataset but the objective of this hands on lab is to inspire you to explore the possibilities of using machine learning for your own research, and not to build the next HR-solution.
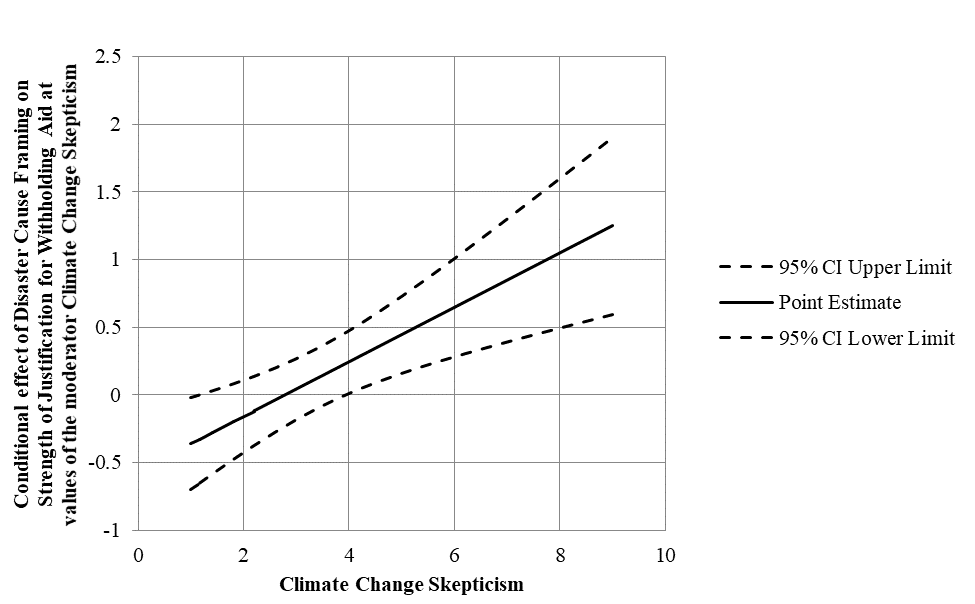
The case that we used is based on the article of Chapman and Lickel (2016), and you can find a detailed elaboration of this case in Andrew Hayes’ second book about Introduction to Mediation, Moderation, and Conditional Process Analysis (Hayes, 2017). You can download the data from Hayes’ website. The datafile you need for this example is called DISASTER. Besides, you can also download the PROCESS V3.0 macro for SPSS and SAS (and much more) from the site: http://www.processmacro.org/
This short blog is about exploring the relationships between stress, satisfaction and self-evaluation. For an assignment of the course Introduction to Psychology, I had to gather 20 responses to answer some questions. Due to the huge amount of responses, I thought it could be nice to share the results to thank all of you for your participation. Continue reading “The effect of Stress on Satisfaction and Self-Evaluation”
This blog gives you some reflections on predictive modeling and human interaction.
The prediction…
The nice thing of predictive modeling is that it gives you possible answers, which you could use to define you or your customers’ actions. You can classify things or trying to predict numbers, like your sales. Another nice thing is that you can retrain your models over time to get -hopefully, but not guaranteed- better results.Continue reading “Predictive modeling and human interaction”
This is a simple example about optimizing prediction models on Azure. In this case we will use a Boosted Decision Tree model. We will show you how you can use the Permutation Feature Performance module to prune your trees.